前回の記事の続きになります。
-

-
【日向坂46】ブログから画像を全自動ダウンロードしてみた②【Python】ウェブスクレイピング練習
前回の記事の続きになります。 Pythonを使ったウェブスクレイピングの実践的な内容です。 日向坂46の公式ブログからブログ内の画像を全自動ダウンロードすることが目標です。 ...
Pythonを使ったウェブスクレイピングの実践的な内容です。
日向坂46の公式ブログからブログ内の画像を全自動ダウンロードすることが目標です。
この記事を読んでもらいたい人
- 日向坂46(特におすし推し)が好きな人
- 画像のダウンロードを手作業でしたくない人
- Pythonを勉強した(したい)けど活用の仕方が分からない人
Pythonの環境構築(準備)や基礎については以下の記事を参照してください
-

-
Pythonの始め方~準備から基礎~
私は、Pythonを習ったことがありません。 いわゆる、独学ってやつです。 独学でも これぐらいのものは作れるようにはなります。 私の場合のPython勉強方 ...
おことわり
- Python歴が浅い&独学のためお見苦しいところはあると思います
- こっちの書き方がいいと指摘があれば、コメントかTwitterで教えてくださると助かります
長くなるのでいくつかの記事に分けたいと思います。
今回で記事になります。
最後にこれまでのコードをまとめておくので使いたい人はコピーしてもらってかまいません。
①では、メンバーごとの情報を集めてリストにしていきました。
②では、ブログから画像をダウンロードしていきました。
③では、ループ構造を作っていきます。
目次
注意点

ウェブスクレイピングは強力な手法ですが、いくつか注意点があるので確認しておきましょう。
これは①と同じなので、既に読んでいる人は本編へどうぞ。
攻撃とみなされる
コンピューターが高速でリクエスト(ページを表示したり、画像をダウンロードしたり)するので、それこそ人ではあり得ないスピードで行うので、相手のサーバーには負荷がかかります。
遅延やサーバーダウンが起こったりします。
一時停止をはさみながらリクエストの頻度を下げる必要が有ります。
利用規約違反
Webサイトによっては、明確にスクレイピングを禁止しているものも存在します。
事前に確認しましょう。
日向坂の公式サイト内には見つからなかったので、節度有るリクエスト頻度なら大丈夫(なはず)。
著作権法違反
Webスクレイピングの対象となる情報に著作権があると、活用方法を誤ってしまうと著作権法違反となるので注意が必要です。
個人的に保存する分にはOKだけど、「自分の物ですよ」って使うのはOUTぐらいの感覚。
私は全画像ダウンロードしたけどこのサイトで公開するとBANですね。
(各自のパソコンでやってね)
スポンサーリンク
ライブラリ

今回、使用する主なライブラリを先に紹介します。
インストールしていないライブラリがあったら各自「pip install」
ここでは、「へーそんなのあるだ~」程度の理解で大丈夫です。
Requests
サイトの HTMLソースを取得します。
ブラウザ上に文字を表示したりするコード。
ブラウザを開いた状態で「F12」を押すと確認できます。
Beautiful Soup 4
Requestsで取得したHTMLコードを解析します。
全体から必要な情報だけ探す時に使います。
pykakasi
ひらがなからローマ字に変換するために使います。
ファイル名をローマ字で付けたいから。
os
フォルダを作ったり、そのフォルダに保存したりするときに使います。
time
高速リクエストをすると怒られるので、1秒待つみたいな指示を出します。
スポンサーリンク
ループ構造を作る

②では1ページ分の画像を取得できたので、ループ構造を作ってブログ全体をウェブスクレイピングしていきます。
ここで、必要なループは
- 個人のブログの1~最後のページまで
- メンバーを1~最後まで
2つのループをつくって完成です。
個人のブログの1~最後のページまで
方針としては
- 今表示しているページをnow_pageでカウント
- 次のページが存在するか確認
- do whileでループさせる
という感じで進めます。
HTMLを確認しましょう
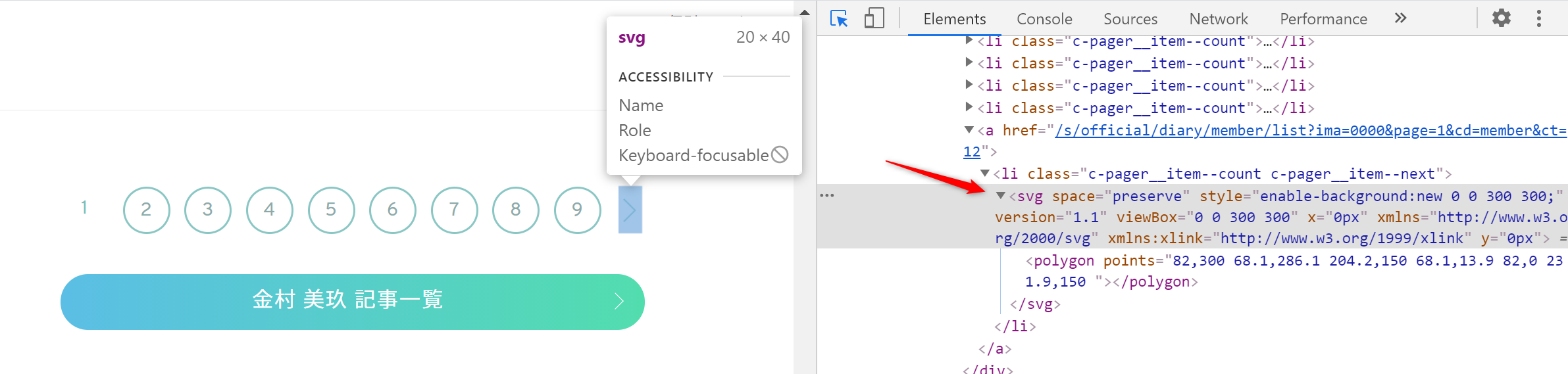
どうやらsvgタグに次のページへのリンクがついている。
このsvgタグがなくなったら終了にすればいい!
next_page = bs4_blog.select('svg')
実行結果
<svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewbox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="82,300 68.1,286.1 204.2,150 68.1,13.9 82,0 231.9,150 "></polygon></svg> <svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewbox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="82,300 68.1,286.1 204.2,150 68.1,13.9 82,0 231.9,150 "></polygon></svg> <svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewbox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="82,300 68.1,286.1 204.2,150 68.1,13.9 82,0 231.9,150 "></polygon></svg> <svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewbox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="218,300 231.9,286.1 95.8,150 231.9,13.9 218,0 68.1,150 "></polygon></svg>
他の場所にも使われているらしい。
svgタグの親タグがliタグさらに親タグがaタグがついているから、これを探してみると
for i in range(len(next_page)):
next_page[i] = next_page[i].find_parent()
next_page[i] = next_page[i].find_parent()
実行結果
<div class="p-button"> <a class="c-blog__profilelink" href="/s/official/artist/12?ima=0000">プロフィール詳細<svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewbox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="82,300 68.1,286.1 204.2,150 68.1,13.9 82,0 231.9,150 "></polygon></svg></a> </div> <a href="/s/official/diary/member/list?ima=0000&page=1&cd=member&ct=12"> <svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewbox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="82,300 68.1,286.1 204.2,150 68.1,13.9 82,0 231.9,150 "></polygon></svg></li></a> <div class="slider-next"> <i class="nextArrow"><svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewbox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="82,300 68.1,286.1 204.2,150 68.1,13.9 82,0 231.9,150 "></polygon></svg></i> </div> <div class="slider-prev"> <i class="nextArrow"><svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewbox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="218,300 231.9,286.1 95.8,150 231.9,13.9 218,0 68.1,150 "></polygon></svg></i> </div>
リンクが付いているはずだから、href属性を探してみる。
next_page[i].get('href')
実行結果
None /s/official/diary/member/list?ima=0000&page=1&cd=member&ct=12 None None
1ページ目だと次のページだけだから1つだけリンクが取れました。
2ページ目で実行すると
None /s/official/diary/member/list?ima=0000&page=0&cd=member&ct=12 /s/official/diary/member/list?ima=0000&page=2&cd=member&ct=12 None None
2つ有りますね。
前のページと次のページですね。
最初と最後のページだけリンクが1つで、それ以外のページは2つですね。
リンクの数で条件分岐していきます。
now_page = 0
next_exist = True
while next_exist:
url = 'https://www.hinatazaka46.com/s/official/diary/member/list?ima=0000&page=' + str(now_page) + '&cd=member&ct=12'
#②の画像ダウンロードパート
next_page = bs4_blog.select('svg')
link = 0
for i in range(len(next_page)):
next_page[i] = next_page[i].find_parent()
next_page[i] = next_page[i].find_parent()
if next_page[i].get('href') != None:
link = link + 1
if now_page == 0:
now_page = now_page + 1
elif now_page >= 1 and link >= 2:
now_page = now_page + 1
else:
next_exist = False
print(name_kanji[9], now_page, 'end')
1行目でページ番号を初期化(0番から始まっています。)
3~5行目でwhile文を設定、next_existがTrueの場合続ける
7行目urlのpage=をnow_pageでループで書き換え
13行目でlinkを初期化(リンクの個数を数える)
15~19行目でリンクの個数を数える(Noneでないものを数えている)
21~26行目で次のページに行くか判断
最初(0)ページ目は必ず次のページへ
それ以降はlinkが2つなら次のページへ
1つならループ終了
28行目で確認
これで1人分のループ終了です。
スポンサーリンク
メンバーを1~最後まで
①でリスト化したメンバー情報をfor文でループさせます。
ここは簡単なのでとばして、次の章で全体をまとめたコードをのせます。
完成形

ここまで長く付き合って頂きありがとうございました。
①~③までをまとめた完成形です。
import requests
import bs4
import os
from pykakasi import kakasi
import time
#ここから①
kakasi = kakasi()
kakasi.setMode('H', 'a')
conv = kakasi.getConverter()
search_url = 'https://www.hinatazaka46.com/s/official/search/artist?ima=0000'
responce = requests.get(search_url)
responce.raise_for_status()
bs4_blog = bs4.BeautifulSoup(responce.text, 'html.parser')
all_member = bs4_blog.select('.sort-default li')
member_No = []
name_kanji = []
name_rome = []
if not os.path.isdir('data'):
os.mkdir('data')
for i in range(len(all_member)):
member_No.append(all_member[i]['data-member'])
name_kanji.append(all_member[i].find('div', {'class': 'c-member__name'}).get_text().strip())
path = os.path.join('data', name_kanji[i])
if not os.path.isdir(path):
os.mkdir(path)
name_kana = all_member[i].find('div', {'class': 'c-member__kana'}).get_text().strip()
last = name_kana.split()[0]
first = name_kana.split()[1]
first = conv.do(first)
last = conv.do(last)
name_rome.append(first + '.' + last)
#①はここまで
for k in range(len(member_No)):
now_page = 0
next_exist = True
while next_exist:
# ここから②
url = 'https://www.hinatazaka46.com/s/official/diary/member/list?ima=0000&page=' + str(now_page) + '&cd=member&ct=' + str(member_No[k])
responce = requests.get(url)
responce.raise_for_status()
bs4_blog = bs4.BeautifulSoup(responce.text, 'html.parser')
article = bs4_blog.select('.p-blog-article')
last_day = 0
No = 0
for j in range(len(article)):
date = article[j].find('div', {'class': 'c-blog-article__date'}).get_text().strip()
date = date.split()[0]
year = date.split('.')[0]
month = date.split('.')[1]
day = date.split('.')[2]
label = name_rome[k] + '_' + year + '_' + month.zfill(2) + '_' + day.zfill(2) + '_'
img = article[j].select('img')
if day == last_day:
pass
else:
No = 0
last_day = day
for i in range(len(img)):
src = img[i].get('src')
file_name = label + str(No).zfill(2)
No = No + 1
fg = True
if '.jpg' in src or '.jpeg' in src:
file_name = file_name + '.jpeg'
elif '.png' in src:
file_name = file_name + '.png'
else:
print(src)
fg = False
path = os.path.join('data', name_kanji[k], file_name)
if not os.path.isfile(path) and fg:
responce = requests.get(src)
time.sleep(1)
if responce.status_code == 200:
print(file_name)
with open(path, "wb") as f:
f.write(responce.content)
else:
print('False', responce.status_code, src)
# ②はここまで
next_page = bs4_blog.select('svg')
link = 0
for i in range(len(next_page)):
next_page[i] = next_page[i].find_parent()
next_page[i] = next_page[i].find_parent()
if next_page[i].get('href') != None:
link = link + 1
if now_page == 0:
now_page = now_page + 1
elif now_page >= 1 and link >= 2:
now_page = now_page + 1
else:
next_exist = False
print(name_kanji[k], now_page, 'end')
まとめ
ここまで3つの記事に分けて日向坂の公式ブログから画像をダウンロードしてきました。
ウェブスクレイピングをしてみて気付いたんですが、プログラミングの基礎が詰まっているなと感じました。
ループや条件分岐、配列と基礎を確認するにはピッタリですね。
Pythonを一通り勉強したって人は挑戦してみてはどうでしょうか?
