Pythonの練習も兼ねて何か作ろうと思い立ち、日向坂46の公式ブログをウェブスクレイピングしてみました。

具体的にはブログ内の画像を全自動ダウンロードするってことです。
最初のブログから手作業で一枚一枚ダウンロードしていたら何日あっても足りないのでプログラミングで何とかしてやろと思い立った訳です。
同じような手順で乃木坂46や櫻坂46のブログから画像をダウンロードできるので挑戦してみてください。
この記事を読んでもらいたい人
- 日向坂46(特におすし推し)が好きな人
- 画像のダウンロードを手作業でしたくない人
- Pythonを勉強した(したい)けど活用の仕方が分からない人
Pythonの環境構築(準備)や基礎については以下の記事を参照してください
-

-
Pythonの始め方~準備から基礎~
私は、Pythonを習ったことがありません。 いわゆる、独学ってやつです。 独学でも これぐらいのものは作れるようにはなります。 私の場合のPython勉強方 ...
おことわり
- Python歴が浅い&独学のためお見苦しいところはあると思います
- こっちの書き方がいいと指摘があれば、コメントかTwitterで教えてくださると助かります
長くなるのでいくつかの記事に分けたいと思います。
最後の記事にはまとめたコードを載せるのでそちらをコピーしてもらえば利用できます。
①では、メンバーごとの情報を集めてリストにしていきます。
目次
注意点

ウェブスクレイピングは強力な手法ですが、いくつか注意点があるので確認しておきましょう。
攻撃とみなされる
コンピューターが高速でリクエスト(ページを表示したり、画像をダウンロードしたり)するので、それこそ人ではあり得ないスピードで行うので、相手のサーバーには負荷がかかります。
遅延やサーバーダウンが起こったりします。
一時停止をはさみながらリクエストの頻度を下げる必要が有ります。
利用規約違反
Webサイトによっては、明確にスクレイピングを禁止しているものも存在します。
事前に確認しましょう。
日向坂の公式サイト内には見つからなかったので、節度有るリクエスト頻度なら大丈夫(なはず)。
著作権法違反
Webスクレイピングの対象となる情報に著作権があると、活用方法を誤ってしまうと著作権法違反となるので注意が必要です。
個人的に保存する分にはOKだけど、「自分の物ですよ」って使うのはOUTぐらいの感覚。
私は全画像ダウンロードしたけどこのサイトで公開するとBANですね。
(各自のパソコンでやってね)
スポンサーリンク
ライブラリ

今回、使用する主なライブラリを先に紹介します。
インストールしていないライブラリがあったら各自「pip install」
ここでは、「へーそんなのあるだ~」程度の理解で大丈夫です。
Requests
サイトの HTMLソースを取得します。
ブラウザ上に文字を表示したりするコード。
ブラウザを開いた状態で「F12」を押すと確認できます。
Beautiful Soup 4
Requestsで取得したHTMLコードを解析します。
全体から必要な情報だけ探す時に使います。
pykakasi
ひらがなからローマ字に変換するために使います。
ファイル名をローマ字で付けたいから。
os
フォルダを作ったり、そのフォルダに保存したりするときに使います。
time
高速リクエストをすると怒られるので、1秒待つみたいな指示を出します。
スポンサーリンク
メンバーごとの情報を集めてリスト化する

ここから本編だから頑張って付いてきてね。
サイトのHTMLを確認
兎にも角にもサイトを確認してみよう。
メンバー紹介のページ(https://www.hinatazaka46.com/s/official/search/artist?ima=0000)で情報を集めます。
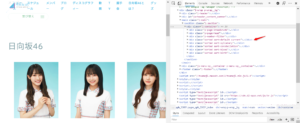
「F12」キーを押してHTMLを確認して、色々探してみるとデフォルト表示されているのが
<div class="sorted sort-default current">
というタグの中にあるらしい
さらに、このタグの中身を確認すると
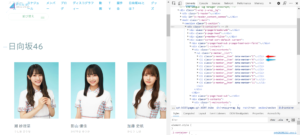
<li class="p-member__item" data-member="数字">
の中にそれぞれの情報が書いてあることが分かりました。
それでは、Pythonでこれらの情報を取得していきます。
import requests
import bs4
search_url = 'https://www.hinatazaka46.com/s/official/search/artist?ima=0000'
responce = requests.get(search_url)
responce.raise_for_status()
bs4_blog = bs4.BeautifulSoup(responce.text, 'html.parser')
all_member = bs4_blog.select('.sort-default li')
1,2行目でRequests, Beautiful Soup 4をインポート(使えるように準備すること)
4行目でサイトのURLを変数に格納
6~10行目でリクエストを送り、取得した情報をresponceへ格納、Beautiful SoupでHTMLを読み取る
12行目で狙ったliタグを取得する
参考
- タグを指定するときは「タグ名」(そのままでいい)
- クラスを指定するときは「.クラス名」(ドットが必要)
タグは<li>や<div>のことです
今回は<li>(リスト)です。
クラスはタグに詳しい説明を加えるもので「class="クラス名"」となっているところ今回は
class="sorted sort-default current"
クラス名は含まれていれば抽出されるのでsort-defaultでおk。
つまり、クラスがsort-defaultのタグの中の<li>を探したってことです。
実行結果はこんな感じで全員分<li>が取れました
<li class="p-member__item" data-member="12">
<a href="/s/official/artist/12?ima=0000">
<div class="c-member__thumb">
<img src="https://cdn.hinatazaka46.com/images/14/a0f/4b9e49b90c090869c7d5e24f8f1f4/400_320_102400.jpg">
</div>
<div class="c-member__name">
金村 美玖
</div>
<div class="c-member__kana">
かねむら みく
</div>
</a>
</li>
メンバー番号を取得
次は各メンバーのブログのURLを確認してみます。
https://www.hinatazaka46.com/s/official/diary/member/list?ima=0000&amp;amp;page='ページ数'&amp;amp;cd=member&amp;amp;ct='メンバー番号'
page=''で何ページ目か?
ct=''でメンバー番号(誰のブログか?)
となっていることが分かります。
<li>内のdata-memberにメンバー番号が振られています。
卒業生の分が欠けているので1から順番に振るとずれてしまいます。
<li>からメンバー番号を取得してリストにします。
all_member[0]['data-member']
all_memberの0番は潮さんでdata-memberの2が取得できます。
(井口さんが1?卒業したからいない)
ということでループを使って全員分リスト化します。
member_No = []
for i in range(len(all_member)):
member_No.append(all_member[i]['data-member'])
1行目で空のリストを作成
4行目で取得したメンバー番号をリストに追加
3行目でループで全員分繰り返す
['2', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24']
こんな感じで22人分リストにできました。
保存用のフォルダを作る
画像を保存していくdataというフォルダを作りましょう。
import os
if not os.path.isdir('data'):
os.mkdir('data')
3行目でdataというフォルダが存在するか確認
4行目でなかったら作る
dataフォルダの中に各メンバーのフォルダを作ります。
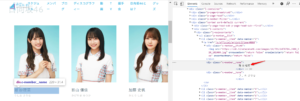
<div class="c-member__name"> 潮 紗理菜 </div>
ここから漢字を探します
all_member[0].find('div', {'class': 'c-member__name'}).get_text().strip()
find()で上の<div>を取得
get_text()でテキストを取り
strip()で余計なスペースを取り除きます
同じくループ処理で全員分リスト化しましょう。
name_kanji = []
for i in range(len(all_member)):
name_kanji.append(all_member[i].find('div', {'class': 'c-member__name'}).get_text().strip())
path = os.path.join('data', name_kanji[i])
if not os.path.isdir(path):
os.mkdir(path)
name_kanjiに取得した漢字名を追加していくところまではメンバー番号と同じです。
文字列を結合してpathを指定します。
data\潮 紗理菜
dataフォルダの中に「潮 紗理菜」フォルダを作るってことです。
これを全員分ループします。
名前をローマ字で記録
ひらがなからローマ字に直す準備をします。
pykakasiを使います。
from pykakasi import kakasi
kakasi = kakasi()
kakasi.setMode('H', 'a')
conv = kakasi.getConverter()
Hがひらがなで、aはローマ字
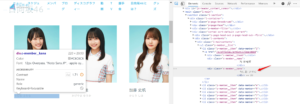
漢字名を取得した手順でひらがな名を取得します
name_rome = []
for i in range(len(all_member)):
name_kana = all_member[i].find('div', {'class': 'c-member__kana'}).get_text().strip()
last = name_kana.split()[0]
first = name_kana.split()[1]
first = conv.do(first)
last = conv.do(last)
name_rome.append(first + '.' + last)
4行目でname_kanaにひらがな名を格納します。
「かねむら みく」のように性と名の間にスペースがあります。
6~7行目のsplit()でスペースで分けます。
['かねむら', 'みく']
とリストで分けられるので0番目が性、1番目が名になります。
9~10行目でpykakasiをつかってローマ字に直しています。
12行目で結合させてリストに追加しています。
['sarina.ushio', 'yuuka.kageyama', 'shiho.katou', 'kyouko.saitou', 'kumi.sasaki', 'mirei.sasaki', 'mana.takase','ayaka.takamoto', 'mei.higashimura', 'miku.kanemura', 'hina.kawata', 'nao.kosaka', 'suzuka.tomita','akari.nibu', 'hiyori.hamagishi', 'konoka.matsuda', 'manamo.miyata', 'miho.watanabe', 'hinano.kamimura', 'mikuni.takahashi', 'marii.morimoto', 'haruyo.yamaguchi']
実行結果はこんな感じ
スポンサーリンク
コードをまとめる

お察しの方も多いとは思いますが同じループ処理をしている箇所があるのでまとめると
import requests
import bs4
import os
from pykakasi import kakasi
kakasi = kakasi()
kakasi.setMode('H', 'a')
conv = kakasi.getConverter()
search_url = 'https://www.hinatazaka46.com/s/official/search/artist?ima=0000'
responce = requests.get(search_url)
responce.raise_for_status()
bs4_blog = bs4.BeautifulSoup(responce.text, 'html.parser')
all_member = bs4_blog.select('.sort-default li')
member_No = []
name_kanji = []
name_rome = []
if not os.path.isdir('data') :
os.mkdir('data')
for i in range(len(all_member)):
member_No.append(all_member[i]['data-member'])
name_kanji.append(all_member[i].find('div', {'class': 'c-member__name'}).get_text().strip())
path = os.path.join('data', name_kanji[i])
if not os.path.isdir(path):
os.mkdir(path)
name_kana = all_member[i].find('div', {'class': 'c-member__kana'}).get_text().strip()
print(name_kana)
last = name_kana.split()[0]
first = name_kana.split()[1]
first = conv.do(first)
last = conv.do(last)
name_rome.append(first + '.' + last)
まとめ
今回は必要な情報をリストにしてきました。
プログラミング言語を触ったことがある人なら簡単だったかな?
分からんみたいな部分はググったりして勉強することが大切です。
もちろん私に聞いても大丈夫です。
次回は画像をダウンロードしていきます。
-

-
【日向坂46】ブログから画像を全自動ダウンロードしてみた②【Python】ウェブスクレイピング練習
前回の記事の続きになります。 Pythonを使ったウェブスクレイピングの実践的な内容です。 日向坂46の公式ブログからブログ内の画像を全自動ダウンロードすることが目標です。 ...